Introduction
SQL queries can return the correct results—but are they doing so efficiently? When working with millions of records, small changes in query structure can have a massive impact on execution time.
One common performance pitfall is using correlated subqueries when a JOIN would be more efficient. While both approaches return the same results, the performance difference can be staggering.
In this post, we’ll benchmark a correlated subquery vs. a LEFT JOIN in PostgreSQL, analyze execution time, and explain why JOINs are usually the better choice for performance.
Setting Up the Benchmark
Imagine you have an e-commerce system where:
- The customers table stores customer details.
- The orders table tracks purchases and references customers.
- You want to retrieve order details along with the customer’s name.
To fetch the customer_name for each order, we can take two different approaches:
1. Use a correlated subquery to fetch the customer_name for each order.
2. Use a LEFT JOIN to retrieve everything in a single pass.
Which one is faster? Let’s find out.
Step 1: Create the Tables
We’ll use two standard tables:
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
name TEXT,
email TEXT
);
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
customer_id INT REFERENCES customers(id),
order_date DATE,
amount NUMERIC
);Step 2: Insert Sample Data
To simulate a real-world scenario, we insert:
- 1 million customers
- 10 million orders
INSERT INTO customers (name, email)
SELECT
'Customer ' || i,
'customer' || i || '@example.com'
FROM generate_series(1, 1000000) AS i;
INSERT INTO orders (customer_id, order_date, amount)
SELECT
floor(random() * 1000000 + 1)::INT, -- Random customer_id
NOW() - (random() * INTERVAL '365 days'),
round((random() * 1000)::numeric, 2) -- Random amount up to 1000
FROM generate_series(1, 10000000);At this point, we have a fully populated database.
Now, let’s compare query performance.
Running the Benchmark
1. Correlated Subquery
A correlated subquery fetches the customer_name for each row in orders.
EXPLAIN ANALYZE
SELECT
o.id,
o.order_date,
o.amount,
(SELECT c.name FROM customers c WHERE c.id = o.customer_id) AS customer_name
FROM orders o;2. LEFT JOIN
Using a JOIN, PostgreSQL retrieves the same data using an hash join.
EXPLAIN ANALYZE
SELECT
o.id,
o.order_date,
o.amount,
c.name AS customer_name
FROM orders o
LEFT JOIN customers c ON o.customer_id = c.id;Benchmark Results
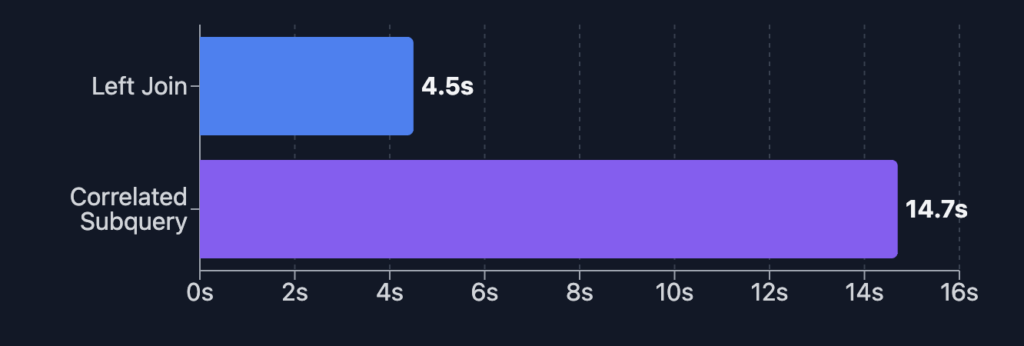
The performance benchmark clearly demonstrates that left join operations execute over three times faster than correlated subquery, completing in just 4.5 seconds compared to 14.7 seconds.
Why JOIN Is Faster
- The correlated subquery runs once per row, meaning 10 million executions in this dataset.
- This forces PostgreSQL to repeatedly scan the customers table for every row in orders, even if an index exists.
- In contrast, JOIN optimizes row lookups by using a hash join.
- The JOIN approach runs in a single pass, reducing execution time by more then 60%.
When To Use Each
- Correlated Subqueries: Handy for complex calculations or when you need row-by-row logic that can’t be easily expressed with a standard JOIN.
- JOINs: The go-to for most scenarios, especially when retrieving related data from multiple tables at scale.
Conclusion
- In this benchmark, using a left join was more then 3x faster than a correlated subquery (4.5s vs. 14.7s).
- If your goal is retrieving related data, join is almost always the better choice.