Introduction
Modern applications often allow end-users to customize fields and attributes in ways developers can’t predict upfront.
For example, consider a project where users needed to create custom resources and define their own attributes. Since a strict relational schema would require constant schema changes and migrations, we will focus on a dynamic data model instead.
To address this, we will explore two common approaches in PostgreSQL:
- Entity-Attribute-Value (EAV): Stores each attribute as a separate row.
- JSONB: Stores dynamic data in a single column per entity.
This post examines the advantages and drawbacks of the EAV model and how PostgreSQL’s JSONB can mitigate many of its challenges. We’ll focus on performance and storage considerations.
Understanding EAV for Dynamic Data on Relational Databases
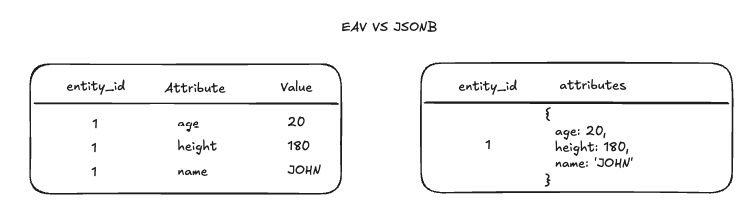
In an Entity-Attribute-Value (EAV) schema, each row represents a single attribute of an entity. Instead of traditional tables with a column for every attribute, you use three columns:
- Entity: An identifier for the item in question (e.g., a user ID or product ID).
- Attribute: The name of the attribute (e.g., age, height, name).
- Value: The content of the attribute itself (e.g., 20, 180, ‘JOHN’).
This design allows you to introduce new attributes freely, simply by inserting rows. You don’t have to modify the table structure whenever users create or rename a field.
In systems where end-users can add or remove fields at will, EAV initially seems appealing. It’s conceptually straightforward, and you won’t need frequent schema migrations.
Downsides of EAV
Despite its flexibility, EAV can suffer from several performance and maintenance drawbacks, especially as data grows in volume or complexity.
1. Query Complexity
When attributes are scattered across multiple rows, pulling together all information for one entity requires joining or aggregating many rows. In practice, this can lead to:
- Complex retrieval logic: If an entity needs multiple attributes, you might have to piece them together from multiple rows.
- Maintenance burden: As more attributes are added, queries become larger and harder to maintain, especially if you must combine many attributes.
For example, retrieving an entity in the EAV model looks like this
SELECT
e1.entity_id,
e1.value AS height,
e2.value AS name,
e3.value AS age
FROM eav_table e1
LEFT JOIN eav_table e2 ON e1.entity_id = e2.entity_id AND e2.attribute = 'height'
LEFT JOIN eav_table e3 ON e1.entity_id = e3.entity_id AND e3.attribute = 'name'
WHERE e1.attribute = 'age';As a result, EAV can dramatically increase the difficulty of writing and optimizing queries—particularly in user-facing systems where custom fields proliferate rapidly.
2. Performance Overhead for Fetching All Attributes
Fetching all attributes for an entity can be particularly inefficient because it often requires multiple joins or aggregation techniques. To retrieve many attributes simultaneously, queries frequently rely on joins, and each additional attribute can introduce another step, increasing complexity and slowing down the query engine.
3. Storage Explosion and Table Growth
EAV can also result in a dramatic increase in table size:
- Duplication of ID Column: Each attribute row stores the same entity identifier repeatedly. This duplication increases the total size of the table on disk.
- More ctids: PostgreSQL internally assigns a “ctid” (a pointer to the physical location of a row). In EAV, every new attribute creates a new row with its own ctid. This can inflate metadata, especially as entities accumulate numerous attributes.
Over time, these factors can lead to a cluttered, less performant system. For user-driven applications where hundreds of thousands (or millions) of attributes might be created, the storage overhead becomes significant.
4. Write Overhead
EAV writes are slow due to the increased table size and frequent index updates. Since each attribute is stored as a separate row, writing multiple attributes of the same entity requires multiple index accesses, leading to higher I/O and increased index maintenance costs, which can significantly impact performance.
PostgreSQL’s JSONB: A Flexible Document Store in a Relational World
To handle evolving data structures more elegantly, many developers turn to JSONB in PostgreSQL. JSONB stores entire sets of attributes in a single column, effectively letting you treat each entity as a small document. This can be a better fit when end-users define fields, as new attributes can simply be nested in the JSON without altering the schema.
JSONB also supports indexing, either with a GIN index for efficient searches across all JSON fields or with expression indexes for specific nested attributes, providing flexibility and performance optimization.
Why JSONB Addresses EAV’s Shortcomings
By consolidating attributes into a single row, JSONB resolves many of the performance pitfalls associated with EAV:
- Lower Query Complexity: Queries can directly return the JSON object or specific fields within it, reducing the need for multiple joins or pivot operations.
- Compact Single-Row Storage: By storing each entity in a single JSONB row rather than splitting it across multiple rows, you significantly reduce redundant metadata (like duplicated IDs and row-level pointers). In turn, this smaller table footprint and lower ctid count translates into faster full table scans, quicker write operations, and smaller overall storage and memory allocations.
- Efficient Writes – Unlike EAV, which requires multiple index updates for each attribute change, JSONB allows updating multiple attributes in a single write operation, reducing index maintenance and I/O overhead. This results in faster writes and improved transaction performance.
For example retrieving an entity on JSONB table would be simple as:
SELECT * FROM jsonb_table WHERE entity_id = 1;Benchmark
To compare performance, we loaded 10 million rows of generated data representing people, each with 7 properties. The benchmark results highlight key differences between EAV and JSONB and this was the results:
| Data Loading | Size | Count Aggregation with Filters | Sort with a Filter | First 1000 Rows | Search for Random Value | |
| EAV | 267s | 171MB | 2.6s | 3.5s | 16ms | 0.6ms |
| JSONB | 130s | 78MB | 0.8s | 0.6s | 1ms | 0.6ms |
Overall, JSONB significantly reduces storage overhead and improves query performance, making it a more efficient choice for dynamic attributes.
The full benchmark can be found here.
When to Still Consider EAV
Although JSONB generally outperforms EAV, certain edge cases might favor EAV:
- EAV B-Tree Index Scans – Efficient for sorting and grouping when querying a single attribute, such as ordering by age or grouping by category. However, as queries become more complex, involving multiple attributes or aggregations, effectively utilizing the index becomes increasingly difficult, leading to performance bottlenecks.
- Better Locking Mechanism – EAV benefits from a more granular locking mechanism, as each attribute is stored in a separate row, allowing updates to different attributes of the same entity to proceed concurrently with minimal contention. In contrast, JSONB updates require modifying the entire column, leading to heavier row-level locks that can block concurrent writes. This can increase contention in high-write environments, especially when multiple transactions attempt to update different attributes of the same entity simultaneously.
However, for most high-scale, user-driven systems, these advantages are often outweighed by the simplicity and performance gains of JSONB.
Conclusion
JSONB provides a practical and efficient solution for dynamic data in PostgreSQL, even though it may not match the performance or structure of a well-designed relational schema.
By consolidating attributes into a single column per entity, JSONB reduces table bloat, simplifies reads and updates, and supports indexing—making it an good choice for systems with rapidly changing or user-defined data structures.
While EAV has niche applications, JSONB is typically the more robust and scalable option for managing flexible data models.